Research Scientist, GDM
sehwag.vikash@gmail.com
I am a research scientist in Gemini core post-training team at Google DeepMind. I work on improving reasoning, RL, and overall post-training effectiveness.
I received my PhD from Princeton University and undergraduate from IIT Kharagpur. My previous experience includes Meta AI, Sony AI, and Microsoft Research.
Summary of Previous Research Work. My current research efforts are focused on enhancing reasoning and RL in Gemini. Prior to this, my research spanned five key areas.
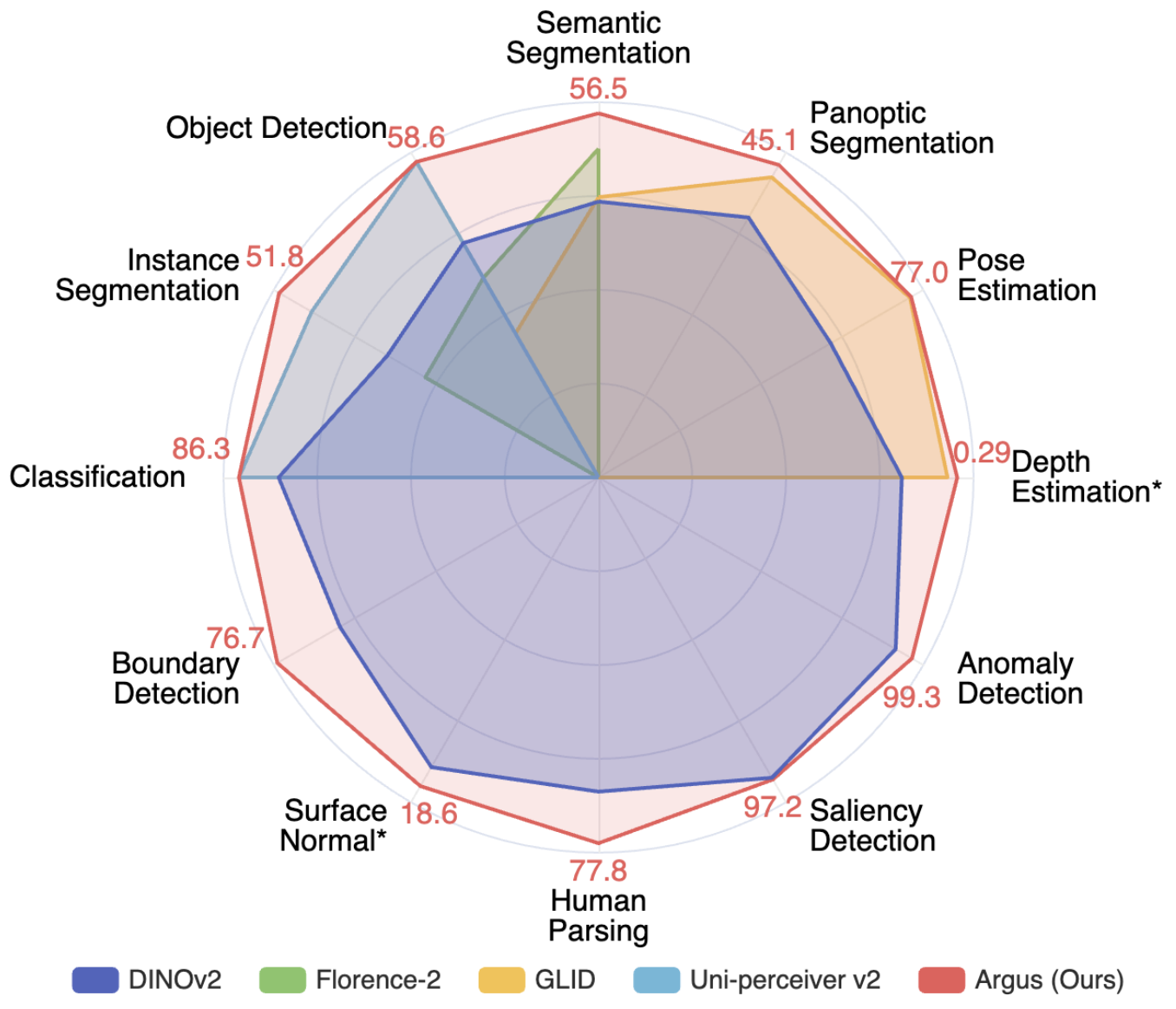
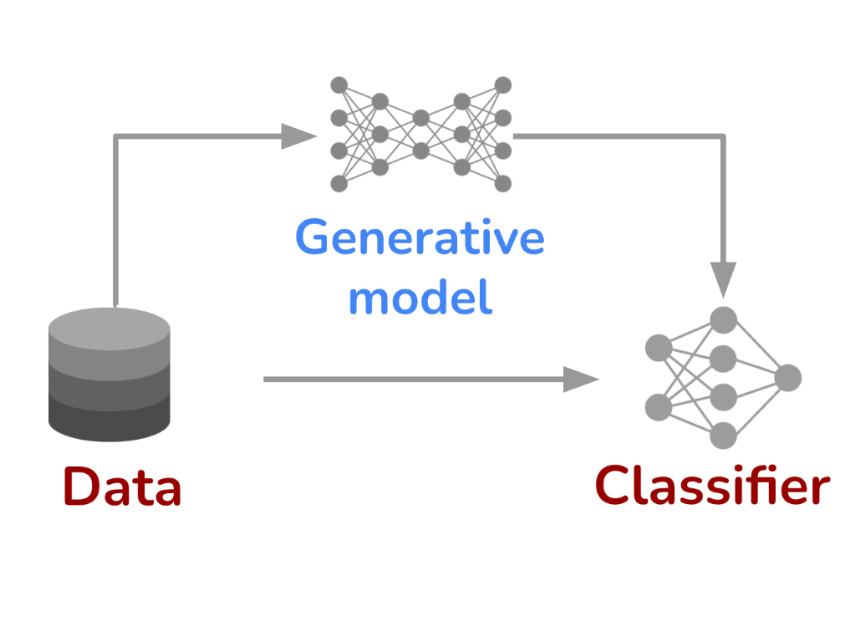
- Democratizing end-to-end GenAI development. I led end-to-end development of text-to-image generative models that cut training cost by 14x (to less than $2,000) while achieving image generation quality comparable to early Stable Diffusion models [1]. I also contributed to the development of a highly compact yet multitask foundation model for vision [2].
- Data provenance in age of GenAI. Concerned by the vast amount of generative content online, we developed techniques to identify synthetic samples [3], even in the absence of artificial watermarks, and tracing them to source generative models [4].
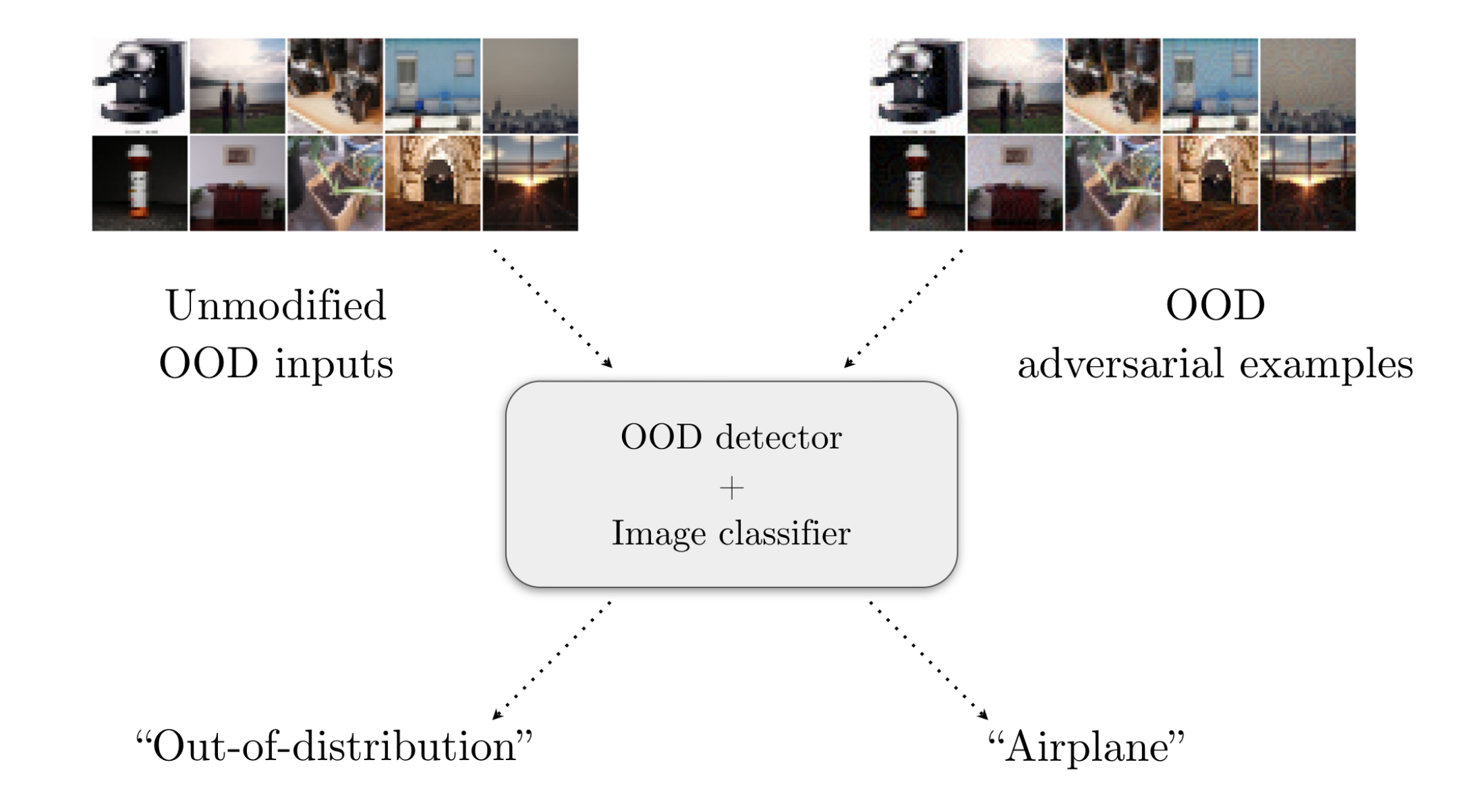
- Safer generative AI. We demonstrated privacy risks in real-world diffusion models and developed privacy-preserving sampling and training methods [5, 6, 7, 8]. We also developed techniques and benchmarked automated generation of adversarial and unsafe content from generative models [9, 10].
- Benchmarking and evals. We developed the widely adopted RobustBench benchmark [11], followed by MultiRobustBench to account for multiple attacks [12], and most recently JailbreakBench [13] to benchmark progress on jailbreaks against LLMs. We have also written a detailed discussion on nuanced similarity and distinction in security and safety approaches towards Trustworthy AI [14].
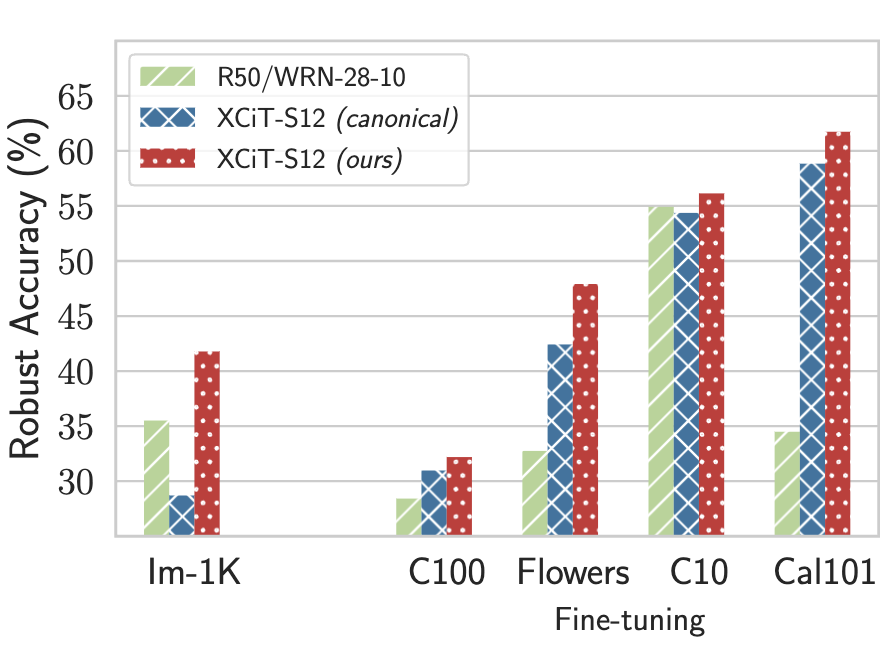
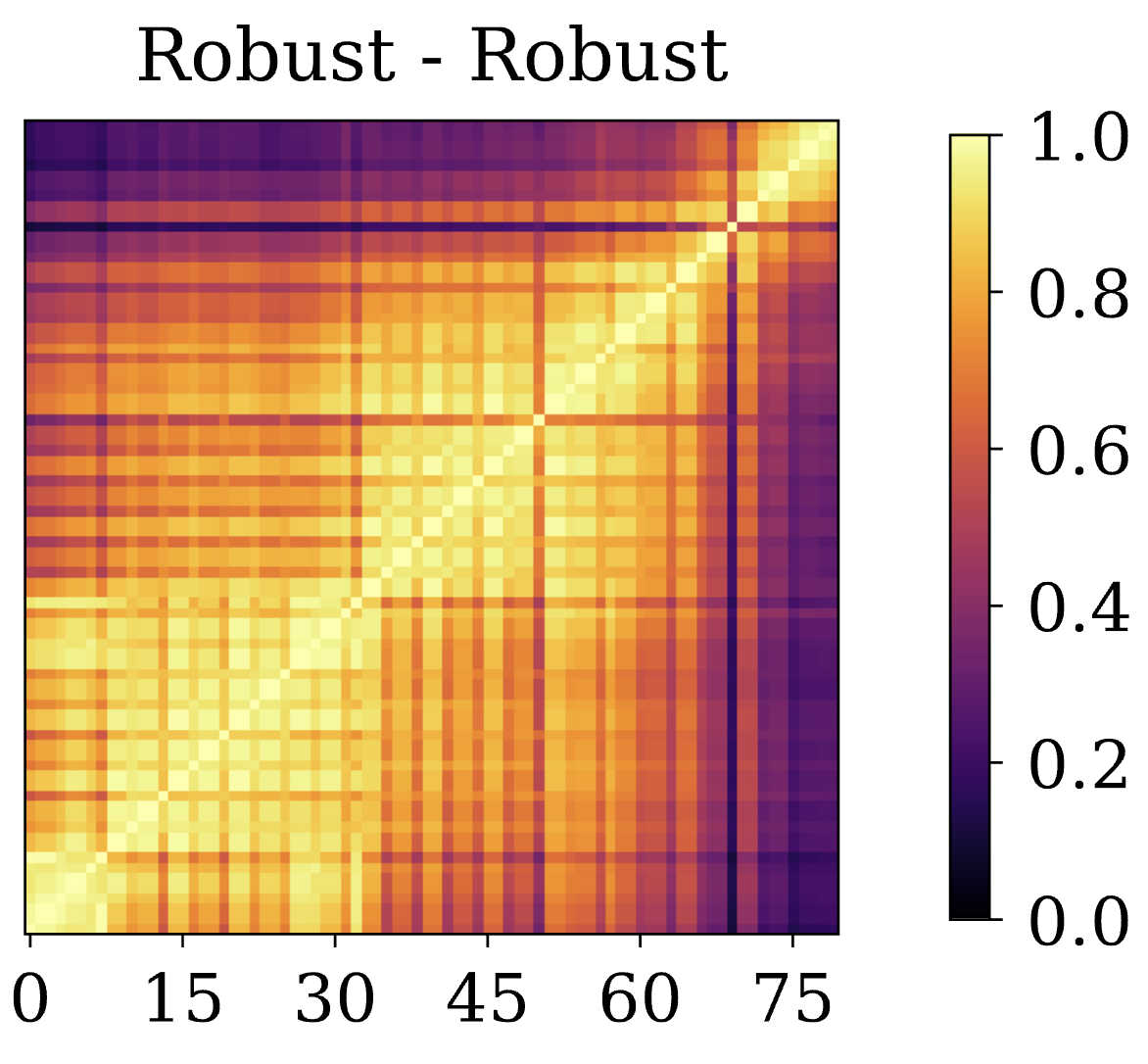
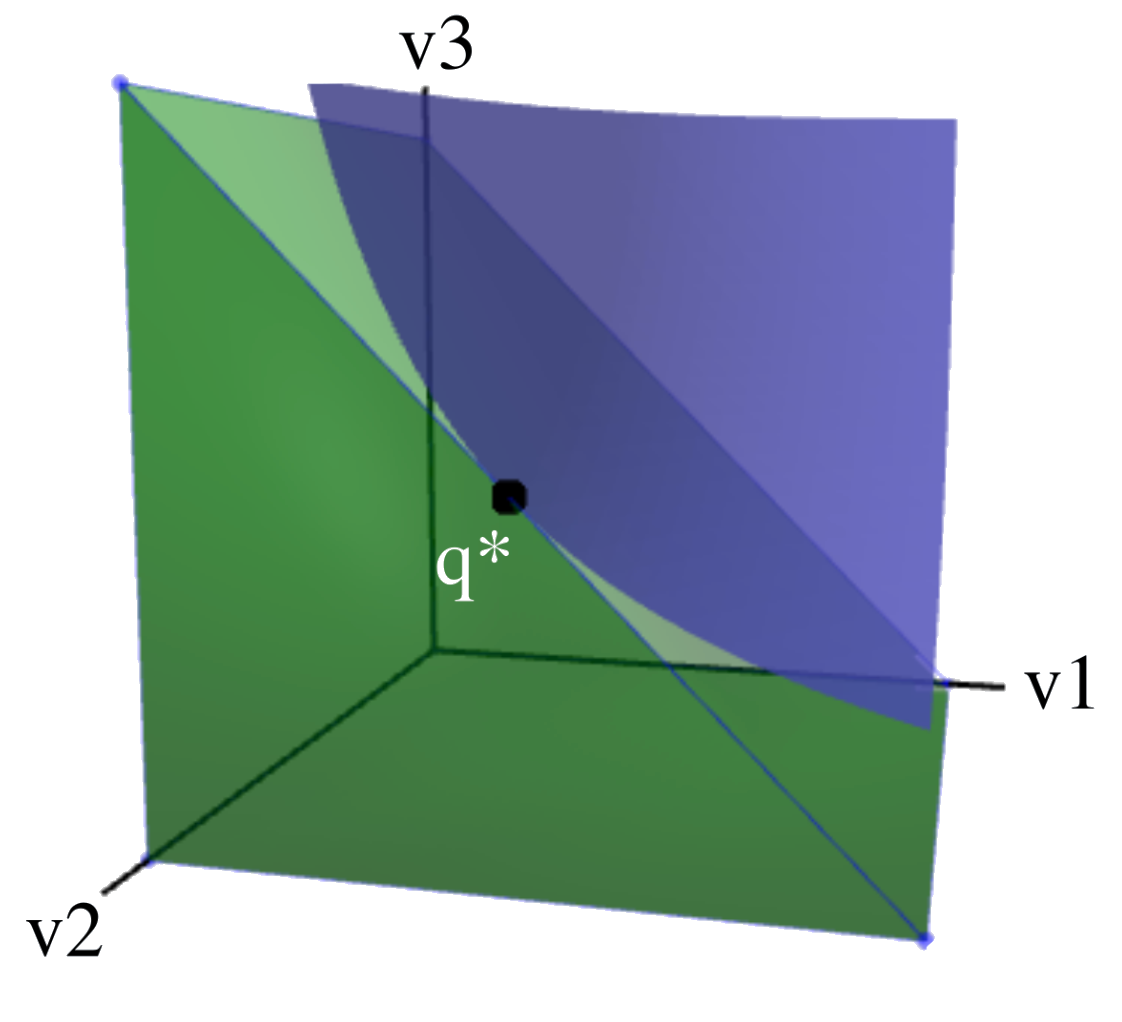
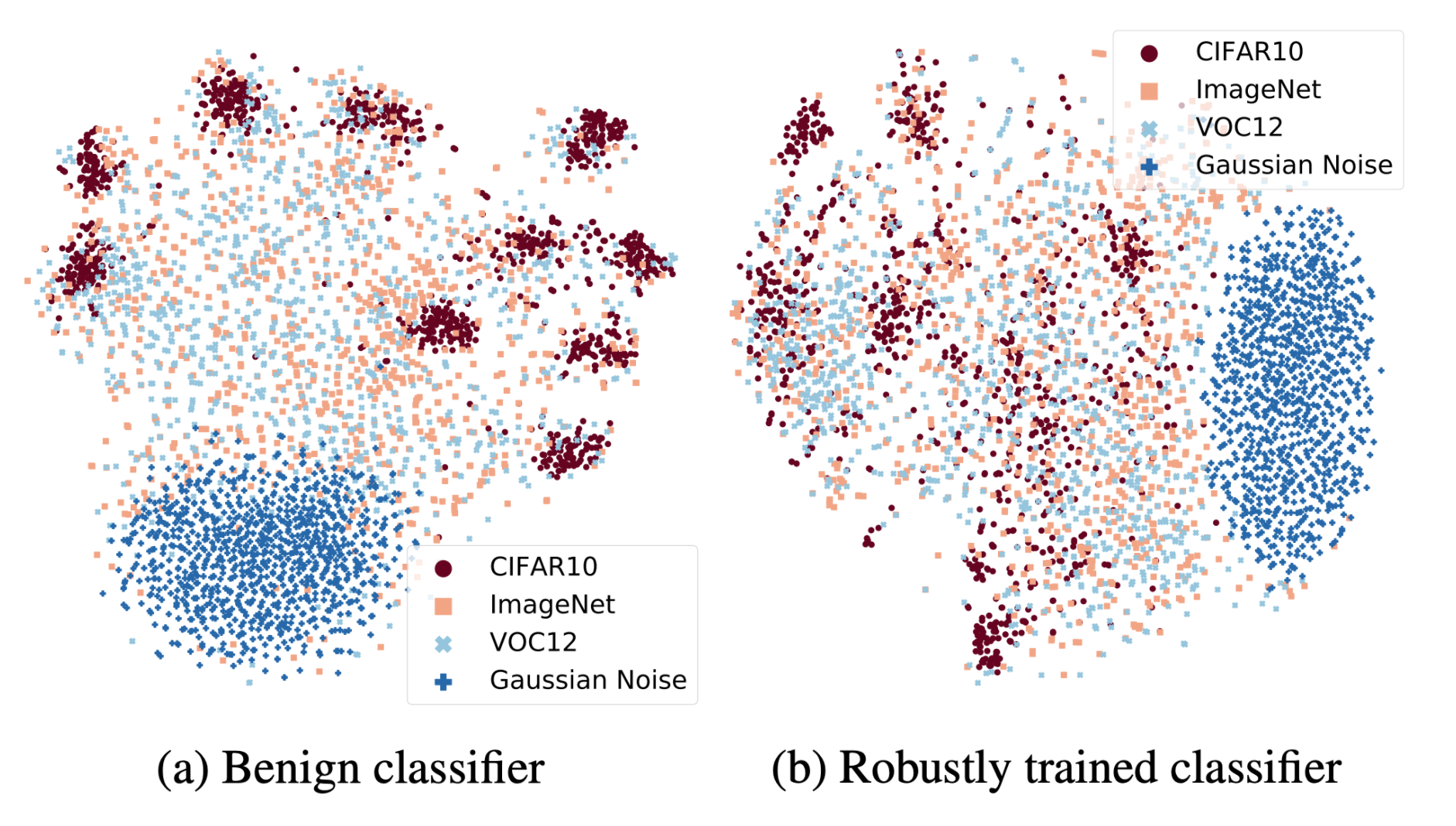
- Robust machine learning. We conducted an in-depth exploration of adversarial robust learning, including circumventing its higher sample complexity using synthetic data [15], finding fundamental limits on robustness [16], demonstrating higher robustness with transformers [17], robustness across threat models [18, 19, 20], the effect of model scaling and compression [21, 22], and adversarial risks in transitioning from closed-domain to open-world systems [23, 24].