If you are excited about generative models, then you would find the latest improvements (e.g., DALLE-2 from OPENAI) nothing less than magical. These models excel at generating novel yet realistic synthetic images [1, 2, 3]. Evident to this success are thousands of dalle-2 images floating on twitter, all of which are photorealistic synthetic images generated by this new model. Even before dalle-2, we have previous works that successfully solve this task on small scale but challenging datasets like ImageNet [1, 2]. A large part of recent progress is fueled by work on diffusion models, a highly successful class of generative models [1, 2, 3, 4].
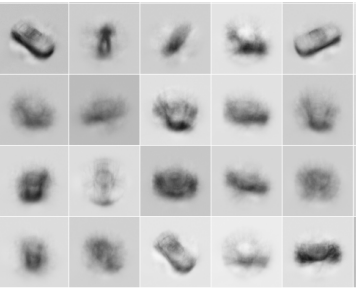
(a) Stochastic-Backprop (Rezende et al., 2014)

(b) GAN (Goodfellow et al., 2014)

(c) Diffusion model (Ho et al., 2020)

(d) DALL·E 2 (Ramesh et al., 2022)
Figure-1. Progress in generative models. Each subfigure presents synthetic/fake images from different generative models across years. While generative models have consistently made progress over years, recent class of diffusion based generative models finally brings the transformative capabilities of generative models to large, diverse, and challenging datasets (fig. c, d). For example, the dalle-2 (fig. d) generative model, which uses a diffusion model, can generate highly realistic images across a wide range of novel scenarios. In this post, I'll mainly discuss how we can improve representation learning using generative models, i.e., by distilling knowledge embedded inside the generative model.
When looking over the super realistic synthetic/fake images from modern generative model, a natural question to ask here is whether we can utilize these images to improve representation learning itself. Broadly speaking, can we transfer the knowledge embedded into generative models to downstream discriminative models. The most common usage of a similar phenomenon is in robotics and reinforcement learning, where an agent first learns to solve the task in a simulation and then transfers the learned knowledge to the real environment [1, 2]. Here the simulator, built by us, acts as an approximate model of real world conditions. However, access to such a simulator is only accessible in certain scenarios (e.g., object manipulation by robots, autonomous driving). In contrast, a generative model learns an approximative model of real world using the training data. Thus for the task of having an approximation of real world model, it shifts the objective from manual designing to learning it from data, an approach that can democratize the synthetic-to-real learning approach. In other words, generative models can acts as universal simulators, due to applicability of their learning based approach to numerous applications. If we can transfer knowledge embedded in these generative models, then this approach has the potential to transform machine learning at broad scale.
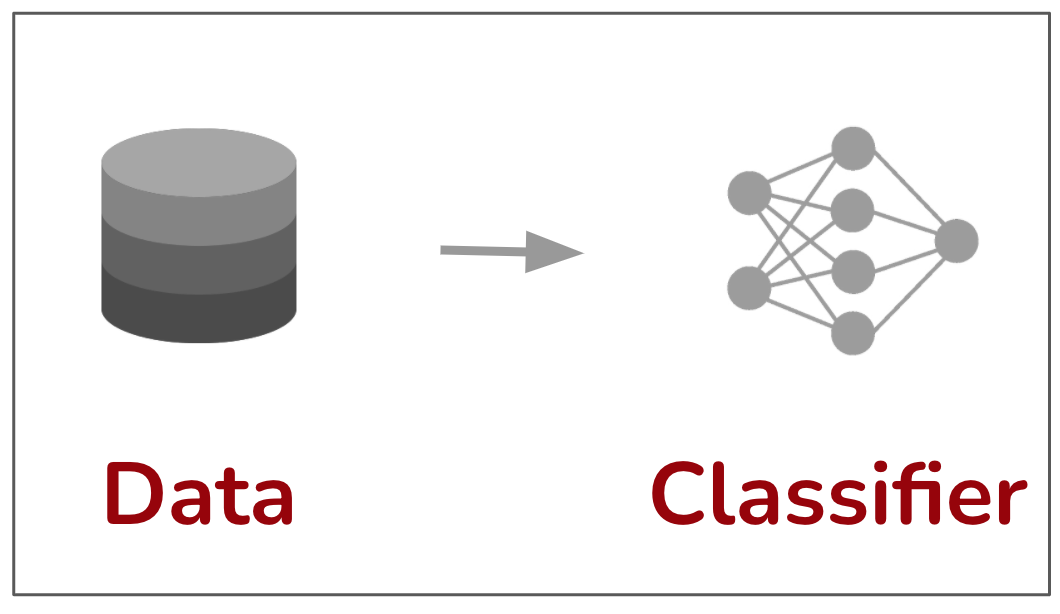
(a) Conventional learning from data
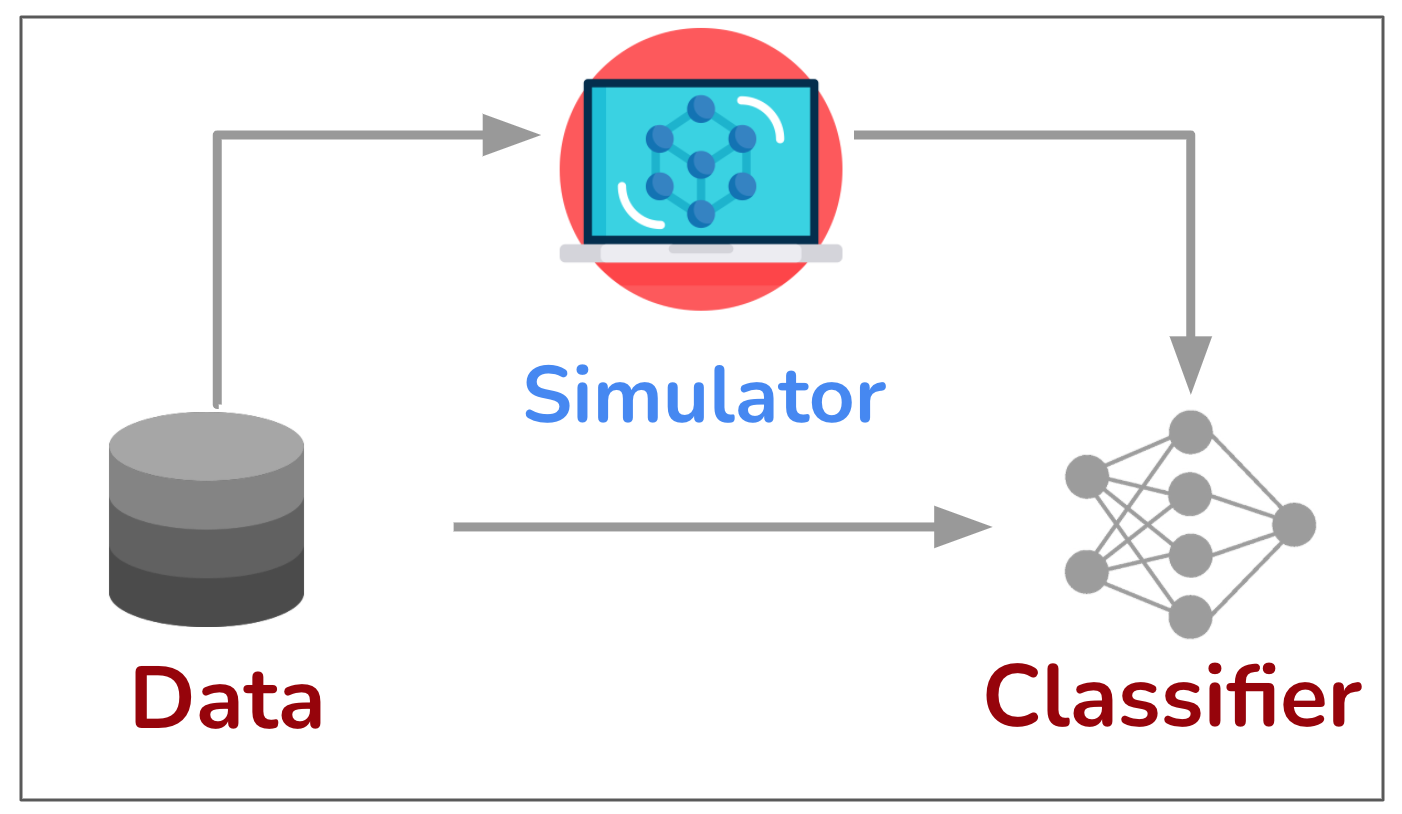
(b) Simulator assisted learning
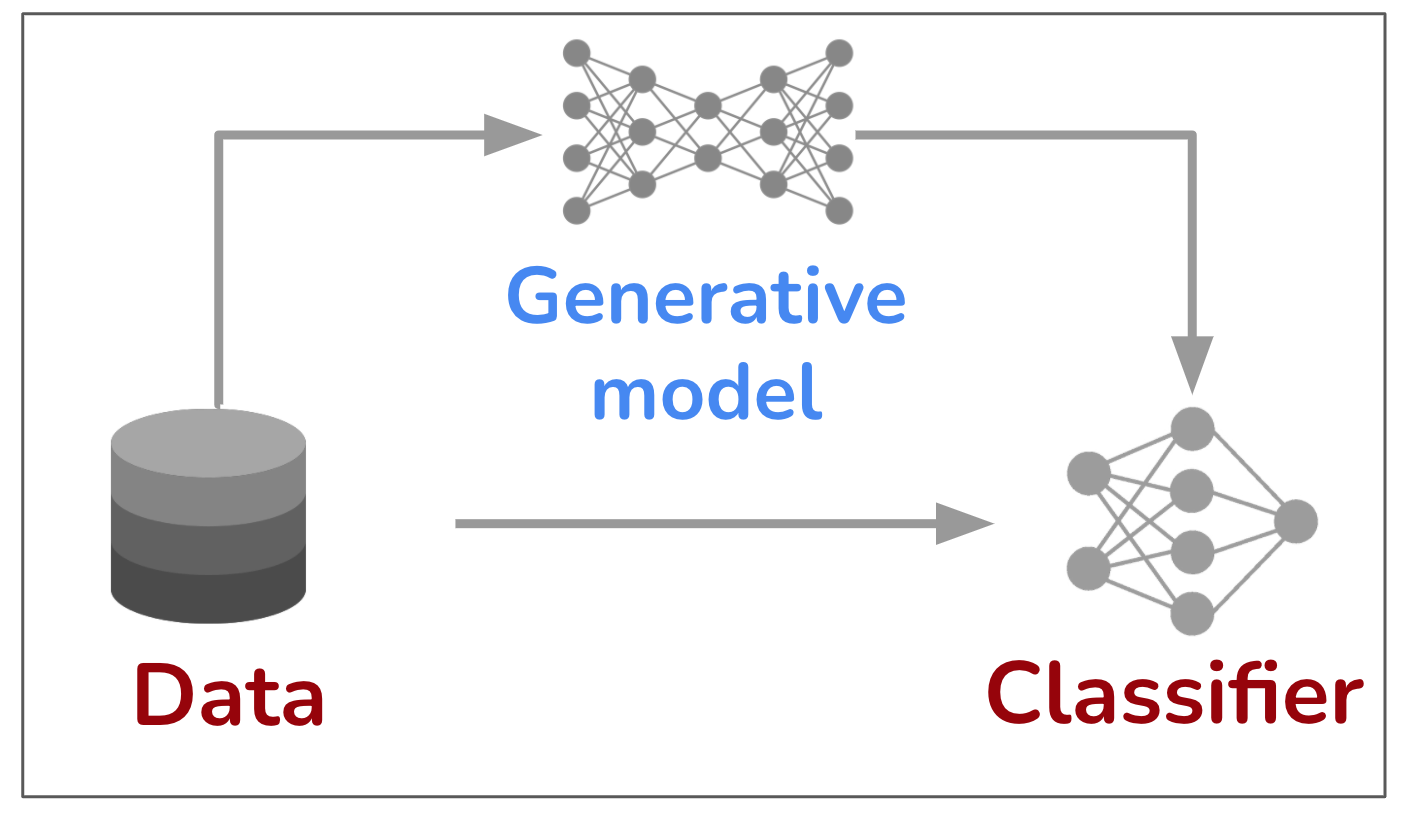
(c) Generative model assisted learning
Figure-2. Democratizing simulation-to-real learning with generative models. When it comes to learning with generative models, one can draw similarities with well established sim-to-real approach [1, 2]. In sim-to-real approach, we first learn representations in a simulated environment and utilize the acquired knowledge in real world tasks. We design such simulators to best immitate real world environment (e.g., in autonomous driving), but such simulators are only feasible for a handful of domains. In contrast, generative models can learn an approximation of real world environment from raw data. So the democratization comes from shifting the problem from designing an approximation of the real world environment to learning it from data, something deep learning is highly effictive at. The concrete research problem is how to best distill the knowledge from generative models for the downstream representation learning. As we will discuss next, the most straightforward way to incorporate generative models is by training on large amounts of synthetic images from it. Surprisingly this simple approach is highly effective in improving performance in common machine learning tasks.
Knowledge distillation from generative models. The success of generative models assisted learning critically depends on how well we can distill the knowledge from it. We may even need customized methods for different generative models. For example, while GANs can be modified to learn unsupervised representations simultaneously with generative models (BigBiGAN), such effective techniques haven't yet been developed for diffusion models. In contrast, a more intuitive and straightforward approach is applicable to all generative models: Extracting synthetic data from generative models and use it for training downstream models. We will consider this approach in most of our experiments in the post. While there is significant room to improve beyond it, it should serve as a common baseline for follow-up methods. I'll further discuss this direction at the end of the post.
Figure 3 summarizes our approach. We start with the images in the training dataset and train a generative model using them. An example would be training a DDPM (Ho et al.) or StyleGAN (Karras et al.) model using the 50,000 images in the cifar10 dataset. Once trained, the generative model gives us the ability to sample a very large number of synthetic images from it. In the following experiments, we will commonly sample one to ten million images. Finally, we combine the synthetic data with the real training images and train the classifier on the combined dataset. The hypothesis here is that the additional synthetic data will boost the performance of the classifier.
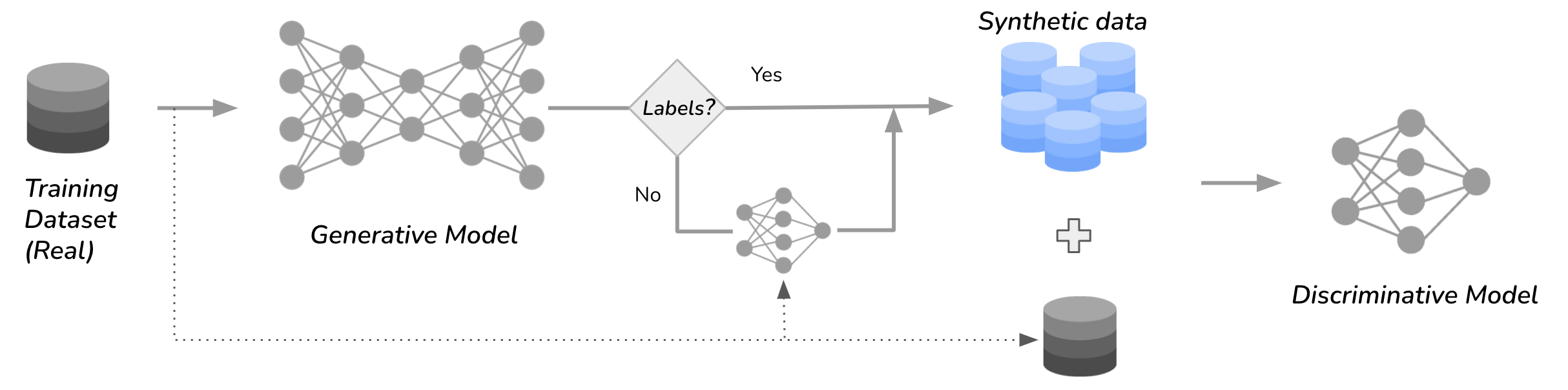
Figure-3. Learning with synthetic data. Overview of the pipeline where we distill knowledge from generative models by extracting a large amount of synthetic data from them and then using it in downstream representation learning.
Part-1: Inflection point with progress in generative models
Using synthetic data from generative models in training is pretty straightforward. But would it help?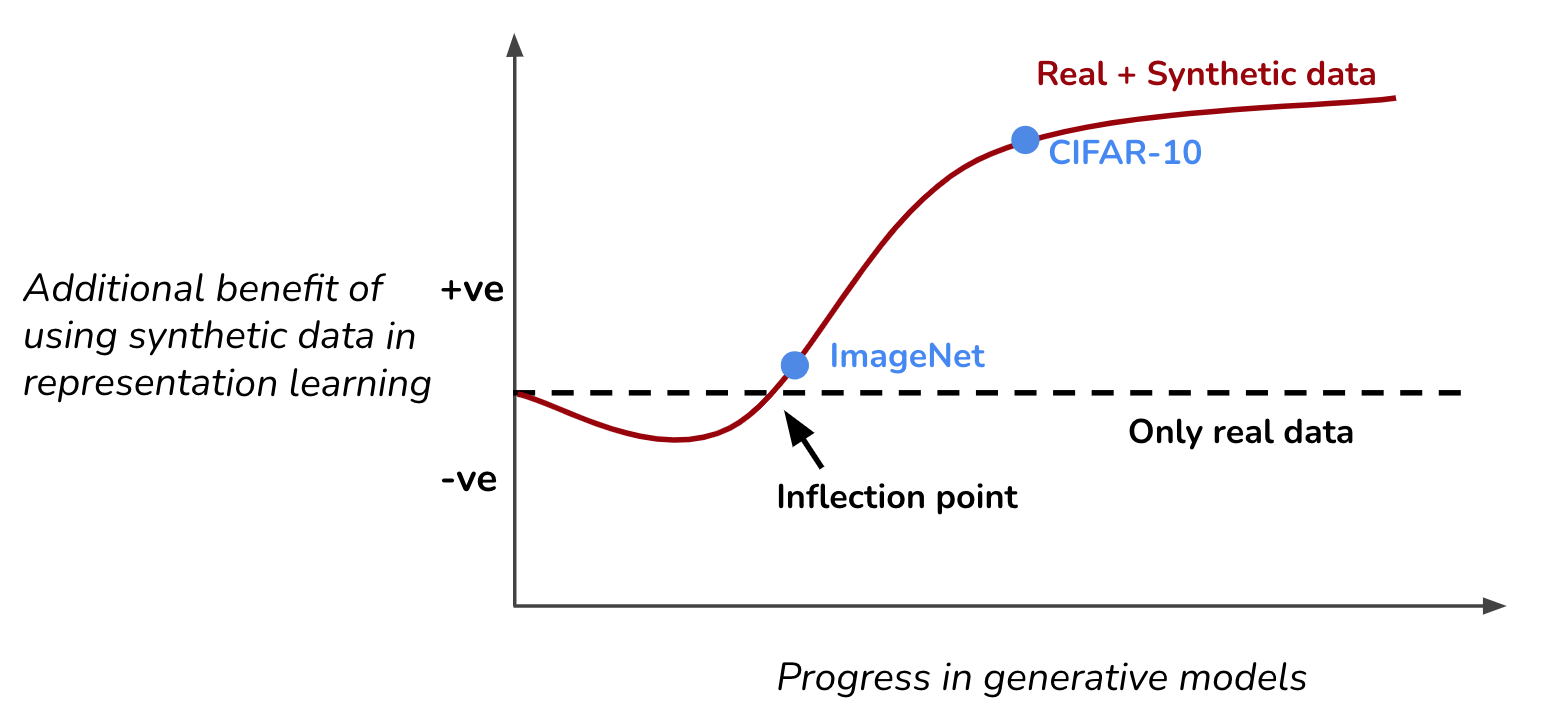
Figure-4. Inflection point with progress in generative models. Our objective is to measure how much additional boost we get in performance when we train a classifier on the combined set of real and synthetic data. At start of progress in generative models, low-quality synthetic data would likely degrade performance. An inflection point occurs when the synthetic data provides an additional boost in performance. On different datasets, we observe a varying degree of progress beyond the inflection point. E.g., we have progressed much farther on cifar10 than the ImageNet dataset.
At start. I would like to argue that it will likely demonstrate an inflection point with progress in the quality of synthetic data. In early stages of progress, the generative model will start to approximate real data distribution, but struggle to generate high fidelity images. E.g., synthetic images from some of the early work on GAN aren't highly photorealistic (fig. 1a, 1b). The synthetic data distribution learned by these early generative models will have a large gap from real data distribution, therefore simply combining these synthetic images with real data will lead to performance degradation. Note that this gap can be potentially minimized by using additional domain adaptation techniques [1].
Near inflection point. With improvement in generative models, one can start generating novel high fidelity images. Progress in generative models is a testament of it, where modern GANs generates stunning realistic image [1, 2, 3], requiring dedicated efforts to distinguish them from the real ones, i.e., deepfake detection [1, 2]. At this point, synthetic data certainly won't hurt the performance, since it lies very close to real-data distribution. But would it help, i.e., cross the inflection point?
Crossing inflection point. To cross the inflection point, we not only need to generate novel high fidelity synthetic images but also achieve high diversity in these images. Synthetic images from GANs often lack diversity, which makes GANs not the most suitable choice. In contrast, diffusion based generative models achieve both high fidelity and diversity, simultaneously [1]. Across all datasets that we tested, we find that using synthetic images from diffusion models crosses the inflection point. Though how much it progresses beyond the inflection point varies across dataset. For example, while synthetic data from diffusion models bring a tremendous boost in performance on cifar10 dataset, it barely crosses the inflection point on ImageNet dataset.
State-of-the-art: Have we crossed the inflection point on common vision datasets?
The short answer, yes. We consider four datasets, namely cifar10, cifar100, imagenet, and celebA. For each dataset, we aim to train two networks. One trained on only real images and the other trained on combination of both real and synthetic images. If latter network achieves better test accuracy, then we claim that the synthetic data crosses the inflection point, i.e., using synthetic data boost performance.
The next question is which experimental setup we should choose to study the impact of synthetic data. The first choice is baseline/benign training, i.e., training a neural network to achieve best generazation, i.e., test accuracy on images. However, we observe that synthetic data is even more helpful across a more challenging tasks, i.e., robust generalization (figure 5-a).
Curious case of robust/adversarial training
The objective in adversarial/robust training is to harden the classifiers against adversarial examples (provide link). Thus the metric of interest is the accuracy on test-set adversarial examples, i.e., robust accuracy. Surprisingly, defending against adversarial examples is extremely hard. State-of-the-art robust accuracy, even on simpler dataset like cifar10, remain quite low. It is well established the generalization with adversarial training requires significantly more data [1]. This high sample complexity of adversarial training likely leads to the higher benefit of synthetic data.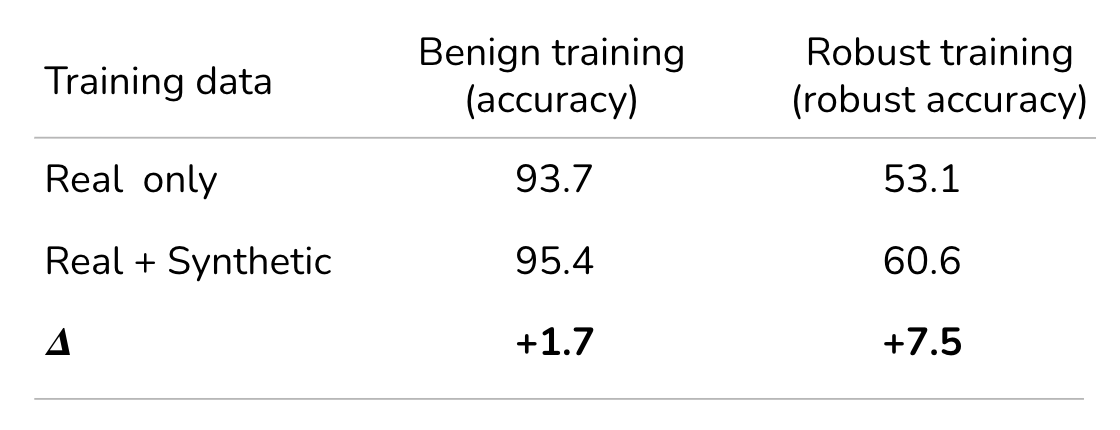
(a) Success in benign and adversarial training.

(b) Success with different datasets in training with adversarial training.
Figure-5. (a) Why study robust training. We first show that the impact of synthetic data is much more significant in robust training then the regular/benign training. This is particularly due to higher sample complexity of robust training. (b) We measure the benefit of training on both synthetic and real images, compared to just real images, on common image datasets.
Across all four datasets, we find that training with combined real and synthetic data achieved better performance than training only on real data (Figure 5-b). However, the impact of synthetic data varies with datasets, e.g., in comparison to cifar10, the benefit on ImageNet is quite small. It brings us to the discussion on the inflection point, where the success of generative models varies across datasets. ImageNet is strictly a harder dataset than cifar (more number of classes, diverse images), making it much harder for generative models to generate both high quality and diverse images on this dataset.
Part-2: Understanding why synthetic helps (its not just about photorealism)
The unique advantage of generative models is that we can sample unlimited amount of synthetic images from them. E.g., we used 1-10 million synthetic images for most experiments. But as we highlighted in figure 4, augmenting synthetic images help only when progress in generative have cross an inflection point. Before we quantify the progress in this section, here is a challenge.



Figure-6. Which generative model is better? Can we identify which of the generative models (DDPM and StyleGAN) yields better quality synthetic images. We measure quality by the generalization accuracy on real images, i.e., when learning from synthetic data, how much accuracy we achieve on real data.
In the figure above, we display real cifar-10 images for synthetic images from diffusion (DDPM) and stylegan based generative model. Our objective is to combine synthetic images from a generative models with real images in training cifar-10 classifier. Consider the following question: Which of the two sets of synthetic images (DDPM vs StyleGAN) will be most helpful, when combined with real data?
Both set of synthetic images are highly photo-realistic, but benefit of ddpm images significantly outperform styleGAN. For example, training with real+ddpm-synthetic images achieves more than 1-2% higher test accuracy than training on real+stylegan-synthetic images on cifar-10 dataset. The difference is even higher than 5-6% with robust training. The motivation behind this question was to highlight the challenge of identifying the best generative model, even for humans. This is because the quality of synthetic data for purpose of represnetation learning depends on both image quality and diversity. While humans are an excellent judge of former, we need a distribution level comparison to concretely measure both.
How real is fake data? Measuring distinguishability of real and synthetic data distributions.
The common approach to measure the distribution distance between real and synthetic data using Fréchet inception distance (FID). FID simply measures the proximity of real and synthetic data using Wasserstein-2 distance in the feature space of deep neural network. So naturally the first approach would be to test if FID can explain why synthetic data from some generative models is more beneficial in learning than others. In particular, why diffusion models significantly more effective then contemporary GANs?
To test this hypothesis, we consider six generative models on cifar10 (five gans and one diffusion model). We first train a robust classifier on 1M synthetic images and measure the performance of real data. As expected, diffusion model synthetic images achieve much higher generalization than other generative models (Table 1). Next, we measure FID of synthetic images from each model. Surprisingly, FID doesn't align with the generalization performance observed when learning from synthetic data. E.g., FID for styleGAN is better than DDPM model while the latter achieves much better generalization performance on real data.
Since the goal is to measure distinguishability of two distributions, we try a classification based approach. If synthetic data is indistinguishable from real, then it would be harder to classify them. We test this hypothesis using a binary classifier. However, it turns out that even few layer neural network swere able successfully classify between real and synthetic data of all generative models with near 100% accuracy.
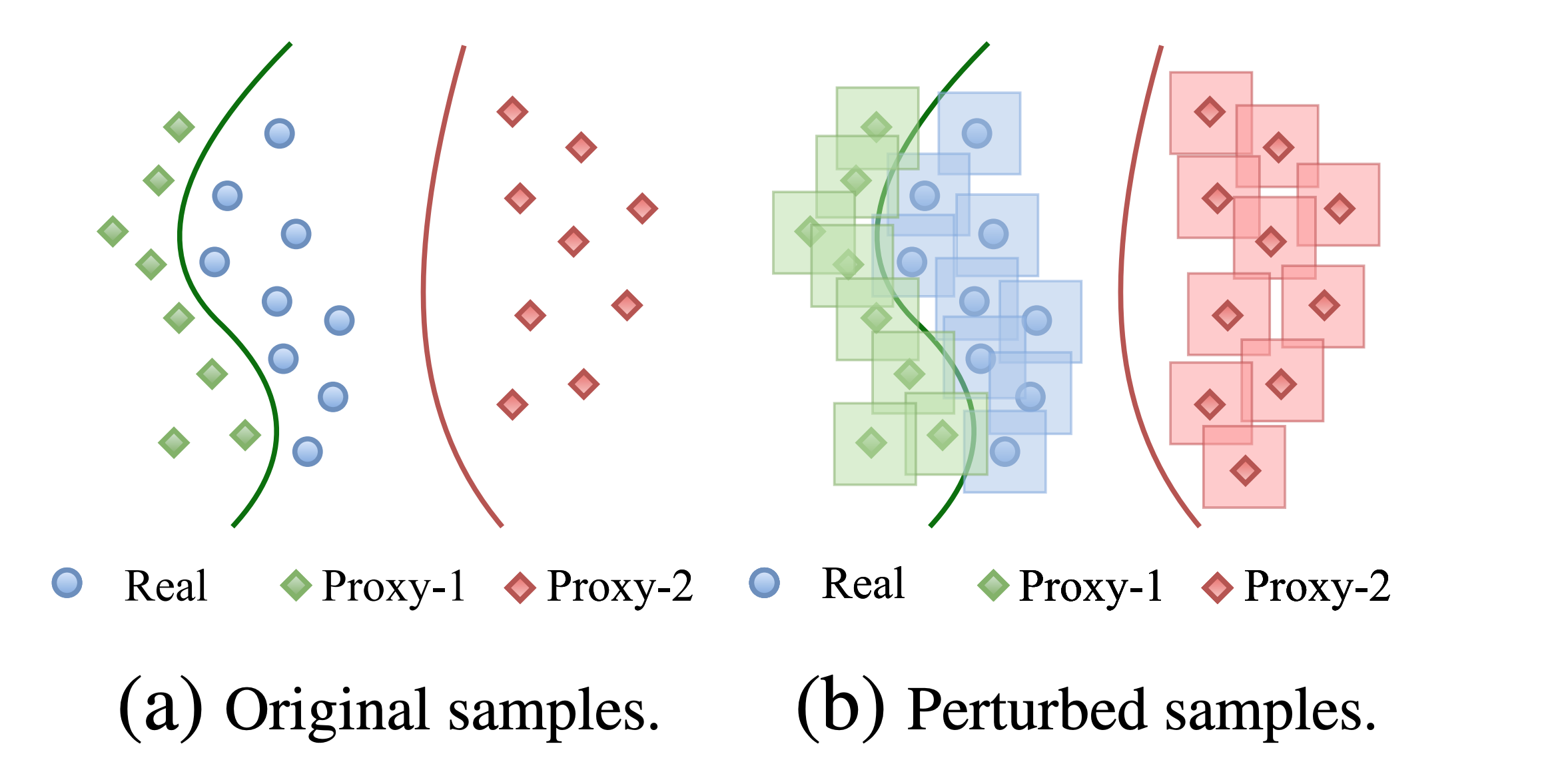
(a) Binary classification beween real and synthetic data. We expand each sample using \(\epsilon\)-ball, which makes classification success dependent on proximity of synthetic data to real data.
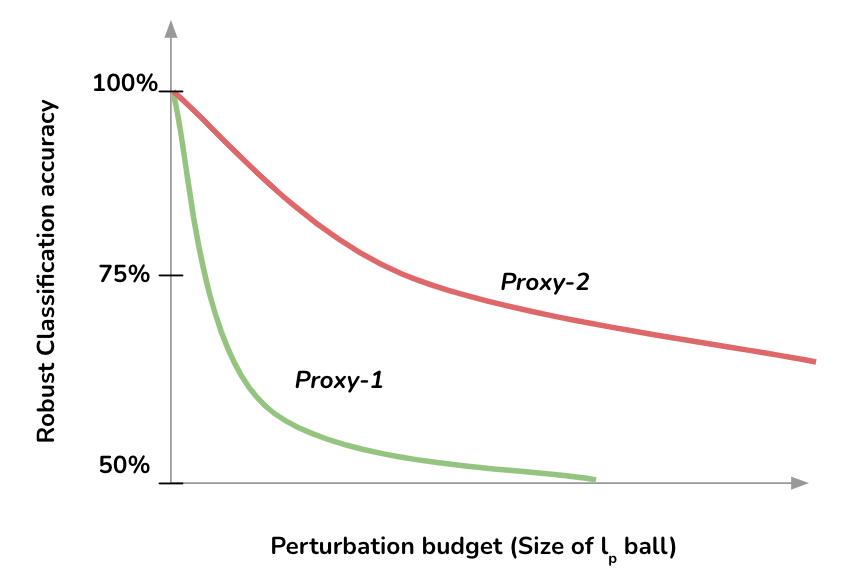
(b) ARC. It refers to the area under the classification success and epsilon(\(\epsilon\)) curve. Lower ARC score implier higher proximity of synthetic data to real data.
Figure-7. When using binary classification as a tool to measure the proximity between synthetic and real data, we encounter an unexpected issue. Even a few layer network successfully classified all synthetic datasets from real. We introduce \(\epsilon\)-balls, i.e., expand each data point using an \(\epsilon\)-radius \(\ell_p\) ball around it and ask the classifier to classify these balls correctly. This simple trick makes the classification success dependent on proximity of real and fake data, since lower proximity will lead to balls intersections, thus making classification inpossible. One can then easily derive a metric (we name is ARC) which measures how hard the classification gets with increase in the size of \(\epsilon\)-balls.
So we need to increase the dependence on discriminator success on distance between real and synthetic data distributions. This can be achieve using a very simple tool: \(\epsilon\)-balls (figure 7.a). We first draw a ball of radius \(r\) (it's a hypersphere if we use \(\ell_2\) norm and a hypercube for \(\ell_{\infty}\) norm) around each data point. Now the objective is to classify all \(\epsilon\)-balls correctly. If the synthetic and real dataset are in close proximity, drawing a decision boundary between them will become hard with small values of \(\epsilon\) itself. We measure the area under the classification success and \(\epsilon\) curve (referred to as ARC). ARC effectively measures the distinguishability of synthetic data from real data.
ARC also explain why synthetic data from diffusion models is significantly more helpful than any other generative model. On cifar10 dataset, ARC values for diffusion mode is 0.06, much lower than the best performing GAN (table-2). It also serves as a better metric than FID in predicting generative model success when their synthetic data is used in augment real data.
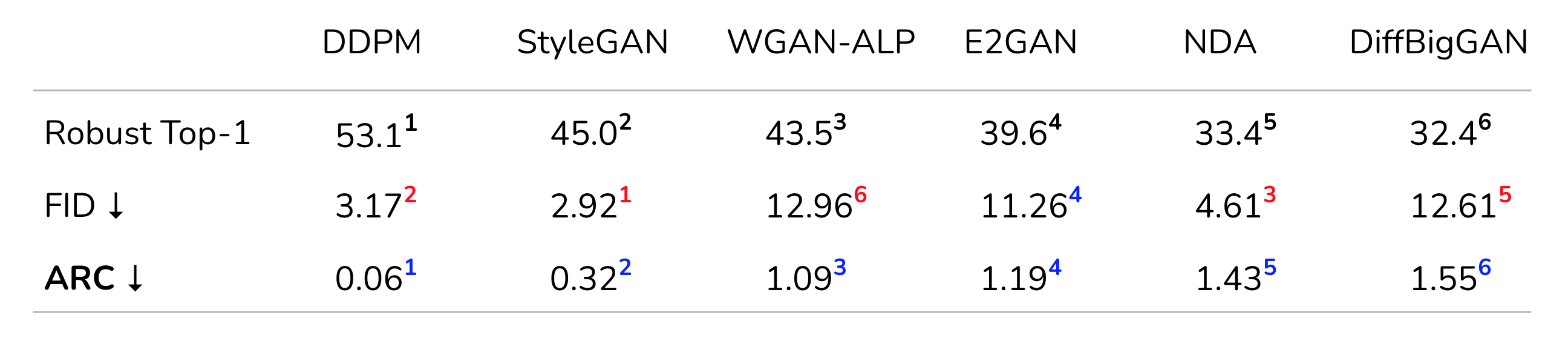
Table-1. Measuring distribution distance between real and synthetic data with ARC (Limitation of FID). Our objective is to test whether the distance between real and synthetic datasets can predict the benefit of synthetic data in classification. For the ground truth, we adversarially train a wide-resnet model on one million synthetic images for each generative model and measure its robust accuracy on real cifar-10 images. Intuitively, if synthetic data is close to real data then we would expect it to provide higher benefit. But how do we measure proximity of synthetic data to real. FID is the most common metric for this task, where it measures the Wasserstein distance between real and synthetic data distribution in the feature space. However, models with better FID (lower is better) doesn't necessarily provide a better performance boost in learning. E.g., FID for styleGAN is better than diffusion model (ddpm) but the latter achieves better generalization on real data. As a solution, we propose ARC, which successfully explains the benefit of different generative models. Especially it explains why dffision models are much better than others since ARC score for diffusion models is much better than all other models in our study.
Discussion
This post is largely based on my recent work that demonstrates benefit of synthetic data diffusion models in robust learning. The motivation to write it was to discuss the potential and bigger picture of how synthetic data can play a crucial role in deep learning, something that the rigid and scientific writing style of a paper doesn't permit.
Robust Learning Meets Generative Models: Can Proxy Distributions Improve Adversarial Robustness?, Sehwag et al., ICLR 2022 (Link)
Diffusion models finally enable the use of synthetic data as a mean to improve representation learning, i.e., move past the inflection point. With further progress in diffusion models, we will likely see higher utility from their synthetic data. However, one doesn't need to limit to using synthetic data as the only approach to integrate diffusion models in representation learning pipeline. In fact, the most important question in the research direction is how to distill knowledge from diffusion models? The current setup, i.e., sample synthetic images and use them with real data is a strong baseline, but has two limitations 1) It treats generative models in insolation to discriminative models 2) In addition, the generative models were trained without accounting that the resulted synthetic data will be used for augmentation in classification tasks. A more harmonious integration of both models will likely further improve performance.
Adaptive sampling. Are are all synthetic samples equally beneficial? We touch upon this question in our work [1] and show that one can get extra benefit from synthetic data by adaptively selecting samples. However, there is so much that can be done in this direction. Ideally we want to sample synthetic images from low-density regions on data manifold, i.e., regions on the data manifold that are poorly covered by real data.
Fine-grained metrics to measure synthetic data quality. To develop adaptive sampling techniques, we essentially need to build measurement tools to indentify quality of different subgroups of synthetic images. In other words, what we can't measure, we can't understand. Metrics such as FID, Precision-Recall, and ARC only provides a distribution level measure of data quality. We would need to develop metric, or tune existing ones, to cater to sub-groups of our datsets.