Research Scientist, Sony AI
sehwag.vikash@gmail.com
I am a research scientist at Sony AI where I lead efforts on enhancing safety and utility of large-scale generative models.
I received my PhD from Princeton University where I was advised by Prof. Prateek Mittal and Prof. Mung Chiang. I previously interned at Meta AI (AI Red Team) and Microsoft Research. I have been fortunate to receive Qualcomm Innovation Fellowship and the Rising Star Award in adversarial machine learning. I previously organized the first seminar series on Security & Privacy in Machine Learning (SPML) at Princeton University.
Research Interests. Uncovering and mitigating safety risks in the development of next-generation of trustworthy AI systems.
- Safer generative AI. We have demonstrated privacy risks in real-world diffusion models and developed privacy-preserving sampling and training methods [1, 2, 3, 4]. We have also developed techniques and benchmarked automated generation of adversarial and unsafe content from generative models [5, 6].
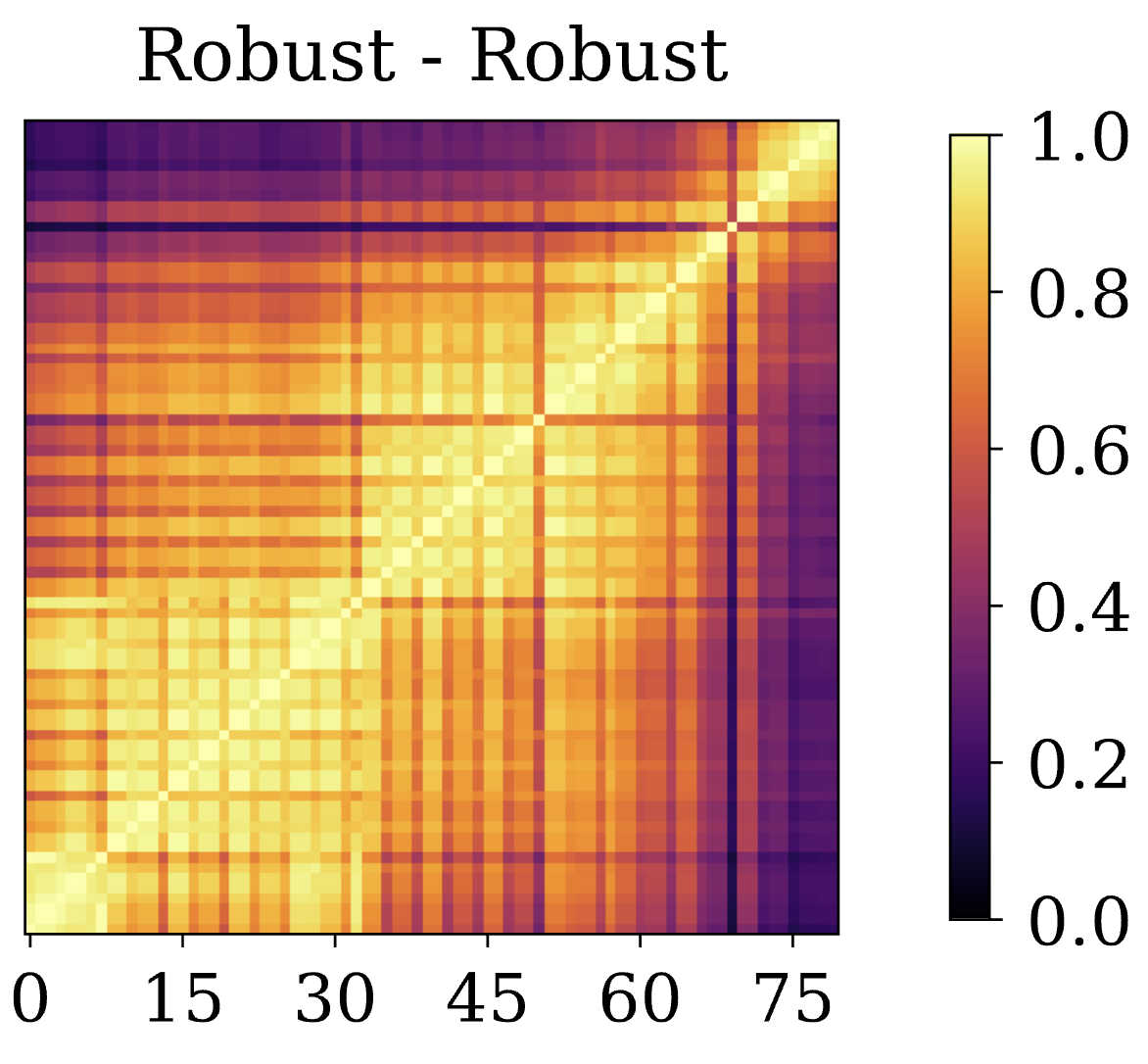
- Responsible data synthesis. Concerned by the vast amount of generative content online, we've recently developed techniques to identify synthetic samples [7], even in the absence of artificial watermarks, and tracing them to source generative models [8].
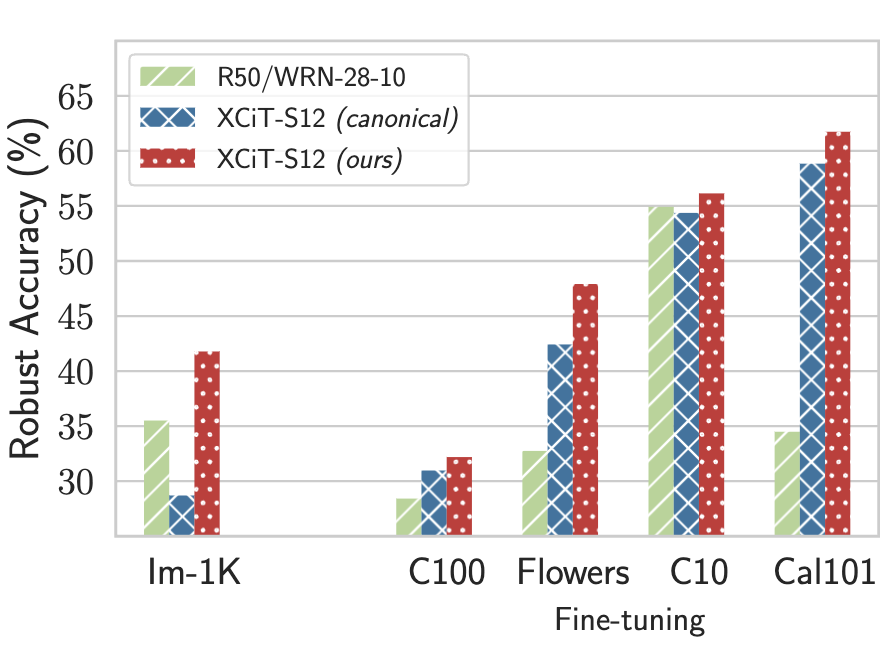
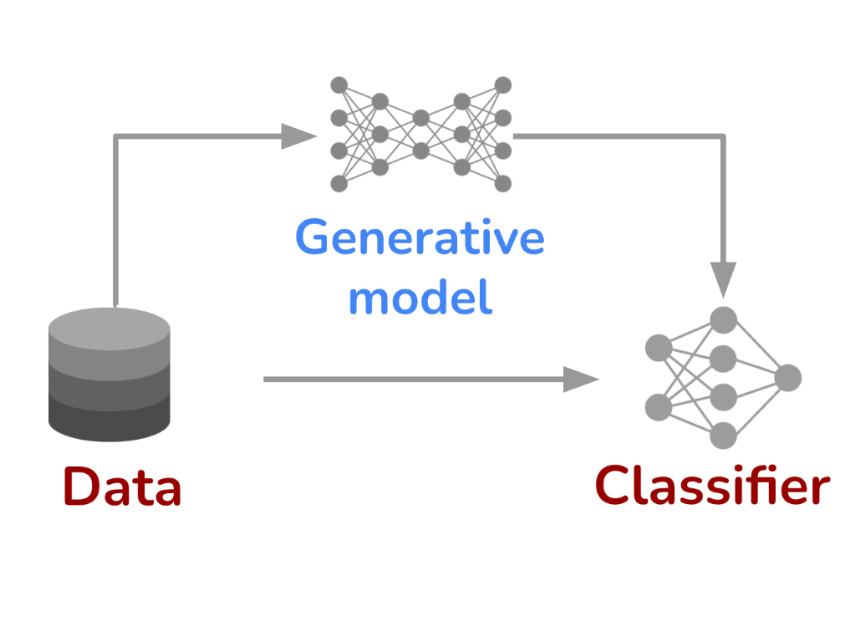
- Robust machine learning. We have conducted an in-depth exploration of adversarial robust learning, including circumventing its higher sample complexity using synthetic data [9], finding fundamental limits on robustness [10], demonstrating higher robustness with transformers [11], robustness across threat models [12, 13, 14], the effect of model scaling and compression [15, 16], and adversarial risks in transitioning from closed-domain to open-world systems [17, 18].
- Benchmarking progress in AI safety. We developed the widely adopted RobustBench benchmark [19], followed by MultiRobustBench to account for multiple attacks [20], and most recently JailbreakBench [6] to benchmark progress on jailbreaks against LLMs. We have also written a detailed discussion on nuanced similarity and distinction in security and safety approaches towards Trustworthy AI [21].